|
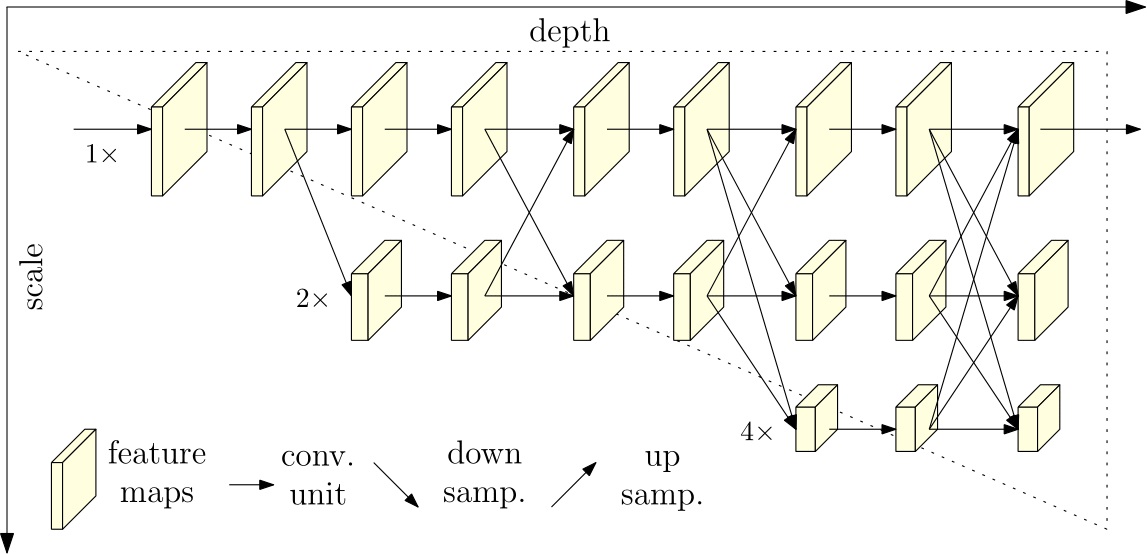
Classification networks have been dominant in visual recognition, from image-level classification to region-level classification (object detection) and pixel-level classification (semantic segmentation, human pose estimation, and facial landmark detection). We argue that the classification network, formed by connecting high-to-low convolutions in series, is not a good choice for region-level and pixel-level classification because it only leads to rich low-resolution representations or poor high-resolution representations obtained with upsampling processes.
|
|
We propose a high-resolution network (HRNet). The HRNet maintains high-resolution representations by connecting high-to-low resolution convolutions in parallel and strengthens high-resolution representations by repeatedly performing multi-scale fusions across parallel convolutions. We demonstrate the effectives on pixel-level classification, region-level classification, and image-level classification.
|
|
The HRNet turns out to be a strong repalcement of classification networks (e.g., ResNets, VGGNets) for visual recognition. We believe that the HRNet will become the new standard backbone.
|